
Stixel is a Medium-level representation of images on traffic scenes, indicating free space, the obstacles ahead and their approximate depth. Usually a stereo image pair is needed to compute the Disparity (Depth) Map. In this post, we introduce a way of computing the Stixels using ONLY a single Monocular Images with a Deeping-Learning manner.
Stixel Overview
There are a number of ways of representing objects on an image. A pixels, for example, is the minimum unit that indicate the brightness of each position on the 2D image plane. An object region, can be considered as a group of pixels where a certain object locates in a particular region: e.g. The car on the figure below. The region contains higher-level visual information (e.g. geometry shape and visual label: car) than pixels. Meanwhile, the higher representation it is, the higher effort it takes to compute, sometimes critical for real-time applications.
A Stixel is a middle-level trade-off between pixels and regions. It is a column of colored pixels on the objects (basically obstacles) that indicates the distance between the objects and our camera.

Stixel Process Flow – using Stereo Images
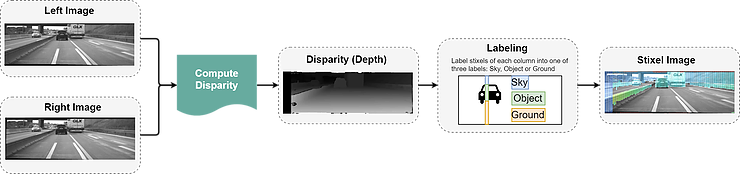
To obtain stixels, first a pair of stereo images are necessary to compute the Disparity (Depth) Map. The map is then segmented into columns with a fixed width. Each column is also segmented into small vertical segments. For each vertical segment, one unique label (either “Sky”, “Object”, or “Ground) is calculated and assigned. The problem then becomes choosing the optimal label for each segment. In the original paper, this classification problem is defined as the minimization of the sum of cost in each segment, where the cost function is composed of two terms:
The Data Term: The error between the actual Disparity and the expected Disparity when given a certain labeling
The Priori Term: Physical assumptions and expectations of each segment. It is independent of input data.
Stixel Process Flow – using Single Monocular Image
You might have noticed that the Labeling relies on the Disparity Map, which is derived from a pair of stereo images. However, in some cases, the only source available at hand might be monocular image and it is still desirable to be able to compute the Stixel Image. It is no longer impossible! Modern Convolutional Neural Network (CNN) now provides us with an alternative method: Depth Estimation Network.
Replace the Disparity Calculation module with Depth Estimation Network, now we can compute the Disparity with a single Monocular image. The process flow now changes to one below. The Depth Estimation Network model is trained to learn pixel-wise disparity (depth) prediction.(Related work: Paper & Implementation) It is also effective for scenes that the network has never seen at training.

Demo
Here comes the demo. The bars on the images indicate where the objects locate and the color shows approximately how far it is. In the bird view, it is a visualization of the distribution of Stixels along z axis in terms of Stixel height. The processing time is about 50ms/frame @i7-7700 CPU 3.6GHz and NVidia 1050Ti GPU.
Discussion & Future Tasks
- With the help of CNN, we are able to compute Disparity with single Monocular Image.
- The network is able to predict approximate depth even if the scene has never shown in the training dataset.
- There may be errors in the depth map if there are objects that the network has never seen before.
- In the Stixel computation, Camera Height is used as a parameter therefore the calculated Stixels are sensitive to vertical bumping, as shown below.



